
Snowflake Field Notes
This is a technical intro to deploying Snowflake data warehouse, as a follow on from my previous post. This may be useful if you have decided to implement Snowflake.


In my first post, I justified an approach to achieve a scalable system for loading, storing, transforming and distributing data within an analytics context.
In this post, we’ll be taking a look into my notebook on storing. Specifically, the things I’ve noted as useful when implementing Snowflake. These few notes, scripts and points of reference should save you some time and get you out onto the water sooner.
Welcome to my pocket notebook, heading Snowflake Important Things - Jan 2020.
Why Snowflake
This isn’t paid content. Though with the flowery praise to come it should be (see contacts below). However, this post doesn't get too far into why Snowflake. Rather it explores how Snowflake. Nonetheless, we may need some justification.
Snowflake’s real value is the reduction of non-value-adding complexity for the user. Putting useful things in your path and keeping anything and everything operationally complex out of your way. Simple as that. If you’ve used PostgreSQL then this shouldn’t feel too foreign, minus index maintenance, table locks, performance issues and upgrades. Pretty standard SQL otherwise, and a few new concepts.
And you only pay for the capacity and performance you use.
That’s it really.
It is just a SQL database. A very fast one, that handles loads of data, and has lots of usability features. It stores data in a columnar way (rather than rows), which means it is very fast. But you’ll still be writing SQL queries, in a mostly familiar pleasant SQL syntax.
The primary alternative to Snowflake in this context is Google Bigquery. I’m no expert, but you’d struggle to go wrong with either. Snowflake offers a choice of AWS, Azure or GCP for your horsepower, so that might be reason enough for you to choose Snowflake. At some point, it should start to become clear that Snowflake is just a clever interface for storage and computation built on commodity cloud infrastructure. Very clever. S3 buckets + EC2 for anyone feeling like they’d rather DIY this part, or build a competitor.
Last part of the intro fanfare: Snowflake is a Data Platform. This is made clear in their recent manoeuvring into the crowded, polluted sea of Data Marketplaces, and a peek into the BI world, with their very simple new Dashboards tool. However, the most platformy move here is a direct integration with Salesforce. More on this in the closing.
Context
This post doesn’t get too far into the details of the doing, but rather points out things that are somewhat peculiar or unique to Snowflake. Things to be kept in mind when doing the initial deployment.
The context also caters entirely towards doing your transforming tasks in a SQL transformation tool like Dataform or dbt.
The structure of this post will loosely follow the order in which you’ll encounter and want to consider various new concepts and features as you implement Snowflake.
We will start with an intro to a Snowflake deployment. We’ll then apply some structure to loading, after getting the security and costs watertight we will finally set sail with some interesting new features and capabilities.
1. Deployment
As of publishing this, you can sign up and get started with a free (no credit card), month-long trial, which gets you floating.
Once you’ve signed up, you’ll need a few things in place as part of the deployment. These include roles, users, databases and warehouses.

New Concepts
The new concepts introduced here are warehouses and credits.
/Warehouses
Essentially a warehouse is how you specify the power of compute that you use to run queries. This is interesting because you can assign a warehouse to a role. TRANSFORM roles can use a different warehouse to REPORT roles. This allows you to fine-tune your compute power and response time for various scenarios. Predictable power for TRANSFORM, snappy and responsive for REPORT to keep the end-users happy!
Warehouses are NOT where you keep your data. Think of a warehouse like a sail that you hoist when the cold query winds blow from the East (or when the warm Summer trade-winds blow from the East depending on your preference).
Practically, a role is granted privileges to use a warehouse in much the same way a role is granted privileges to access a database. A warehouse also needs to be specified whenever a connection is made to Snowflake.
grant all privileges on warehouse WAREHOUSE_REPORT
to role ROLE_REPORT;/Credits
You get billed based on your usage of credits.
Credits are consumed by storage and warehouses.
Every time* you start a warehouse, you pay per second in credits, and so credits are effectively your unit of currency.
At the time of writing a credit is $2-$3, and negotiating that down when your annual contract value reaches ~$10k is the typical script.
The outcome of this warehouse/credit scenario is you have a very granular cost breakdown of your query costs.
*Not every query starts a warehouse - see cached data section below.
Additional Notes:
See a walkthrough of cost calculations, product tiers and implications here.
Permissions
This is the grant <PERMISSION> to <ROLE> part of the database deployment process.
I like to follow either one of the following two deployment patterns:
The Proof Of Concept (POC) keeps things as simple as possible, while still being stable and scalable.
The Production option adds some additional structure on top of the POC.
1. Proof of Concept
This setup doesn't distinguish between PROD and DEV, and rather relies on branching features later on in the transformation, which is perfectly fine.
At the core are the 3 roles, with each only having the permissions necessary to function, without the ability to interfere with the other roles’ domains.
INGEST
Loads data
Can create schemas in
RAWdatabase
TRANSFORM
Creates transformation scripts
Can read data in
RAWCan create schemas in
ANALYTICS
REPORT
Read-only access to
ANALYTICS
This is shown in the relationship diagram below, where connections indicate permissions assigned.
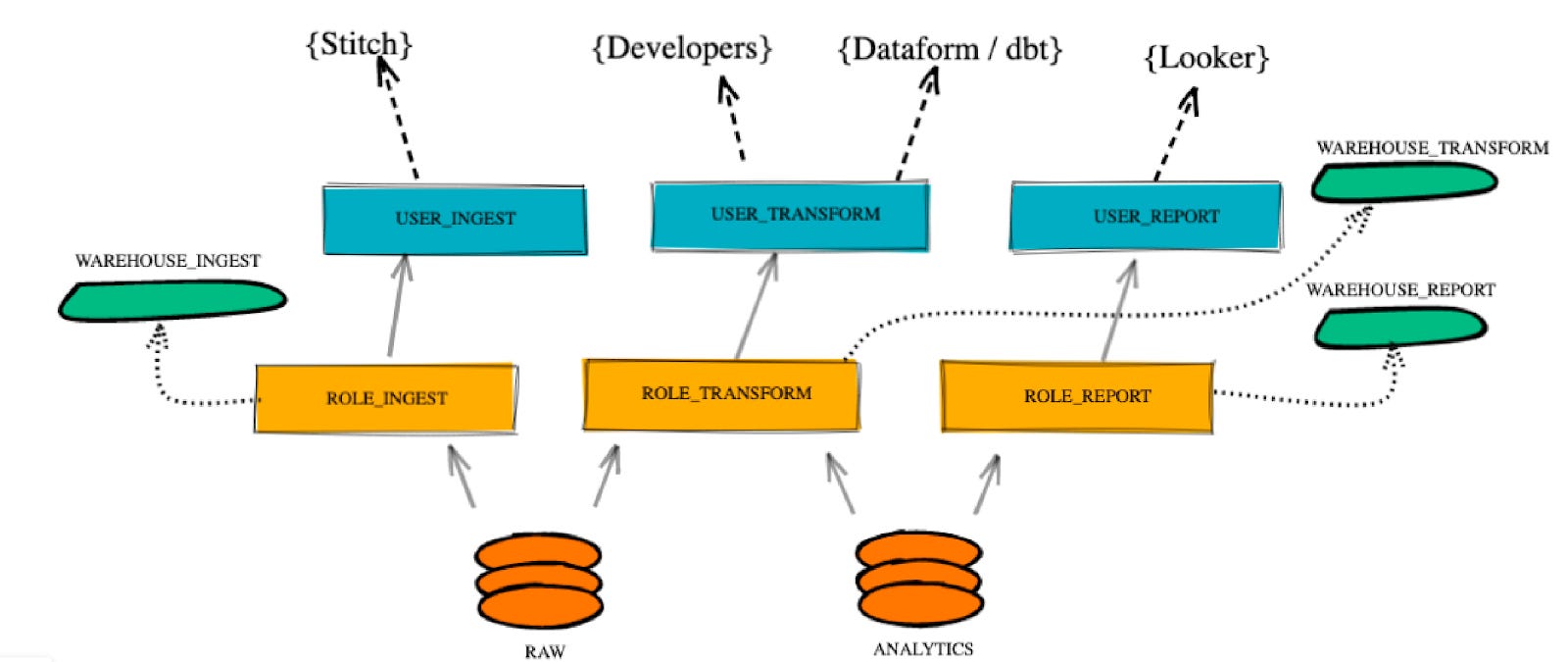
You’ll notice in the diagram that the USER_REPORT cannot access the RAW data, this is an entirely deliberate move towards ensuring that downstream tools cannot build a dependency on RAW data.
For further clarification on how all this works, I’ve created a starter kit for Snowflake, which creates the above diagram exactly, ready for a POC. If you’re considering a Snowflake implementation, it is well worth an hour to take a look. Pull requests welcome!
2. Production
The following configuration takes the basics from the Proof Of Concept and enhances them to include a more robust separation between PROD and DEV. There is a duplication of all entities with _PROD with a _DEV version (_DEV not shown in this diagram for simplicity) and distinct role breakdown for accessing Databases.

Additional Notes:
Snowflake case sensitivity is subtly different to PostgreSQL.
Unquoted object identifiers are case-insensitive
“ANALYTICS” = ANALYTICS = analytics
Create a user for every connecting system, and a user for every developer. This will enable you to track the source and cost of all queries.
If you already have a Snowflake database, you can visually analyse your setup with the snowflakeinspector.com, great for tracking poorly configured snowflake permissions that you may inherit.
A very useful bit of code is the
grant on futuresnippet, which allows you to grant all future tables in a schema with a certain permission.
grant usage on future SCHEMAS in database RAW to role TRANSFORM
grant select on future TABLES in database RAW to role TRANSFORM2. Extract and Load Nuance

/Loaders
If you are using Stitch, Fivetran or similar, you can target your data warehouse at this point. Assign the tool the appropriate role, warehouse, database and schema as specified in the deployment script (ROLE_INGEST, WAREHOUSE_INGEST, RAW).
Stitch will create a schema based on the name you give to the job, so stick with something scalable. I like <loader>_<source> format, so you’ll start with something like STITCH_HUBSPOT. It’s key to note that this means you can later pop out the stitch part for a FIVETRAN_HUBSPOT or an ETL_HUBSPOT.
/JSON
Managed ELT tools will load data as best as they can, typically as rows and columns, but often will insert your data as raw JSON into a single column. This is a good thing. It allows you to become familiar with the incredibly useful Snowflake JSON SQL syntax.
If you write any custom ELT scripts, ensure when loading data to load all data as JSON variant type. This is the crux of ELT. Schemaless loading means your data lands without any notion of a schema, and so you can define the schema later on in one go in the transformation step. This can be seen as a big step, but it helps to be able to define ALL transformations in the transformation stage, and not have to go back to your Python scripts to add new fields.
Additional Notes:
Start with a tutorial for handling JSON in Snowflake, just to get the basics.
3. Secure the perimeter
At this stage there is a risk of moving too fast, and that awkward speed wobble is avoided by taking stock and balancing the books.
The pre-retrospective things to attend to are Costs and Sensitive Data.
Costs
Snowflake is a powerful tool, and with the largest warehouse running into the thousands of dollars per hour, you want to do two things:
/Set a budget and limit
Determining what you are willing to spend in a month is a good start, and setting a policy to alert you at various increments of that amount will avoid a broadside attack from Finance. Setting the policy to disable future queries across specific warehouses or all of them is a good trip switch to ensure that you aren’t caught at sea.
/Get alerted
Worse than running up a large bill (depending on who you ask) would be for your credit limit policy to come into play the moment you click run when demo’ing your fancy analytics to a client or stakeholder.
For this reason, keeping close tabs on spikes in credit usage and becoming familiar with how and where your credits are going is very high on your new agenda. Remember this is SaaS, i.e. Operational Expense. All the costs lay ahead of you on this one.
SnowAlert is a tool that Snowflake maintains. I’ve adopted some of the queries as part of my suggested monitoring in the Snowflake-Starter repo. The queries look for spending spikes across the infrastructure and will return results only if they detect a spike.
Last thing on cost management and this is more of an opinion.
Historically, database resources are specified against a budget for their max expected load. This left lots of performance headroom for the median query. One could view Snowflake costs with some equivalency to this performance headroom, in that a Snowflake query could run faster if you assign it a larger warehouse at increased cost.
However there is a premium being paid for the flexibility, and so it benefits you to manage your fleet of warehouses carefully, lest they turn on you. Snowflake is an operational expense. This is a subtle shift. The crux is that every credit spent should “deliver value” in a somewhat meaningful way.
Additional Notes:
Snowflake caches results of queries, meaning that you won’t get charged for queries that hit the cache. This requires some nuance when modelling credit intensive processes like incremental updates. See this blog for a run-through.
Snowflake charges lightly for access to metadata queries, this is because each time your transform tool runs, it queries the schema definition heavily. This was free, it now isn’t. The cost is negligible but it is worth noting what is going on.
Sensitive Data
/Masking
Snowflake’s “Dynamic Data Masking” feature isn’t quite as dynamic as it sounds but is a welcome addition. You’ll create or replace masking policy EMAIL_MASK and attach that to a role. See this video for an explanation. This is a helpful addition to be able to define masks at an object level. This is a new (enterprise only) feature and works in conjunction or in addition to the standard masking features.
/Access Control
Enable a network policy that whitelists the IPs of Stitch, your BI tool, VPN etc.
Enable multi-factor authentication (MFA) with the Duo app. Duo is GREAT. It prompts for a password protected authorisation on your phone’s home screen. No excuses. All users assigned the ACCOUNTADMIN role should also be required to use MFA.
4. Setting Sail
Snowflake at this point, like setting sail, depends on where you want to go. In my previous post, I outlined what I’d do next, and it looks something like setting up a few data loading tools, writing transforms in Dataform and then distributing the results in an analytics tool. If you haven’t, please check it out.

I will not be overemphasising this section, but rather point out a few of the most interesting features that fall under analysing data. You could at this point treat Snowflake like you would a very tiny t2.tiny PostgreSQL instance, forget about it (other than the $) and continue.
New features in themselves are not always so interesting, but what is interesting is what they enable when combined with existing features. As in technology, so in databases.
/Swap With
alter database PROD swap with STAGESwaps all content and metadata between two specified tables, including any integrity constraints defined for the tables. Also swap all access control privilege grants. The two tables are essentially renamed in a single transaction.
It also enables a Blue/Green deployment, which in simple terms means: Create a new database with your changes (STAGE), run tests on that, if they pass, swap it with PROD. If an hour later you realise you’ve deployed something terrible, swap it back.
/Zero copy clone
create or replace table USERS_V2 clone USERSCreate an instant clone of Tables, Schemas, and Databases with zero cost (until you change the data). Great for testing, development and deployment.
/Time Travel
Combining the clone function, one can time travel to a table as it existed at a specified time (1 day back on the standard plan, 90 days on enterprise). The command below will recover the schema at the timestamp (wayward DROP perchance).
create schema TEST_RESTORE clone TEST at (timestamp=> to_timestampe(40*365*86400));/External functions
Run a call to a REST API in your SQL. Great for those pesky ML functions.
select zipcode_to_city_external_function(ZIPCODE)
from ADDRESS;Closing Meta Industry Thoughts
Snowflake is building a platform, meaning they are building the one-stop-shop for your data needs. The notion of Data Loading is likely going to become more fringe. Snowflake has already moved in this direction with Salesforce.
Einstein Analytics Output Connector for Snowflake lets customers move their Salesforce data into the Snowflake data warehouse alongside data from other sources. Joint customers can consolidate all their Salesforce data in Snowflake. Automated data import keeps the Snowflake copy up to date.
This off-the-shelf analytics is a reasonable next step, perhaps in this case due to investment by Salesforce into Snowflake, but that aside, the data space is finding where lie its layers of abstraction, and this is shown in these industry moves.
Snowflake is building a platform, doing it well, and charging you for it. Engineering time remains expensive, and so outsourcing this to Snowflake’s managed platform will be a welcome relief. However there are no free lunches, and Snowflake is building something bigger than a data warehouse. What this means is that if you take too much, you’ll be stuck with too much.
Echoing Dremio, there is always a thought towards a modular data architecture “that’s built around an open cloud data lake* (e.g S3) instead of a proprietary data warehouse”. I generally agree with this premise. Snowflake is built on top of AWS or Azure or GCP, and so is (was) a thin layer on top of raw storage and compute.
* More on data lakes here
Snowflake is marching towards the abstractions seen in Software Engineering, where every job is a feature for them to build. Snowflake has built Data Warehouse Engineer, it is building ETL Engineer and will likely build Data Engineer in some version soon.

“It is not the ship so much as the skilful sailing that assures the prosperous voyage.” - George William Curtis
Please comment if you have any feedback on any of this, I aim to improve with your help.
Thanks to Dan Lee for reviewing and contributing to this post.
Please consider subscribing for more on the subject of data systems thinking
What is group by 1
Who is Matt Arderne